

Smart Extraction: Turning Document Chaos into Real Business Value
By: Gerrit van Dyk | May 13, 2026
With the first term of 2026 already behind us, time flies, and the year is in full swing. Many of us in business know only too well how overwhelming the flood of documents has become. Last year, global data creation reached approximately 181 zettabytes, and this year it is projected to grow significantly to around 221 zettabytes. With unstructured data – think contracts, invoices, medical records, and compliance forms – making up 80 to 90 percent of that volume, it is no wonder so many organisations still feel buried under paperwork.
Manual processing is not only time-consuming and expensive; it drains energy and takes focus away from what truly matters – serving customers, growing the business, and making sound decisions. This is where “smart extraction” comes in. At the heart of Intelligent Document Processing (IDP), smart extraction turns messy, unstructured documents into clean, actionable data. The IDP market, valued at about USD 10.57 billion in 2025, is expected to reach USD 14.16 billion this year and grow to USD 91 billion by 2034 at a remarkable CAGR of 26.2 percent. These numbers tell us one thing clearly: smart extraction is no longer a nice-to-have – it has become essential for any forward-thinking organisation.
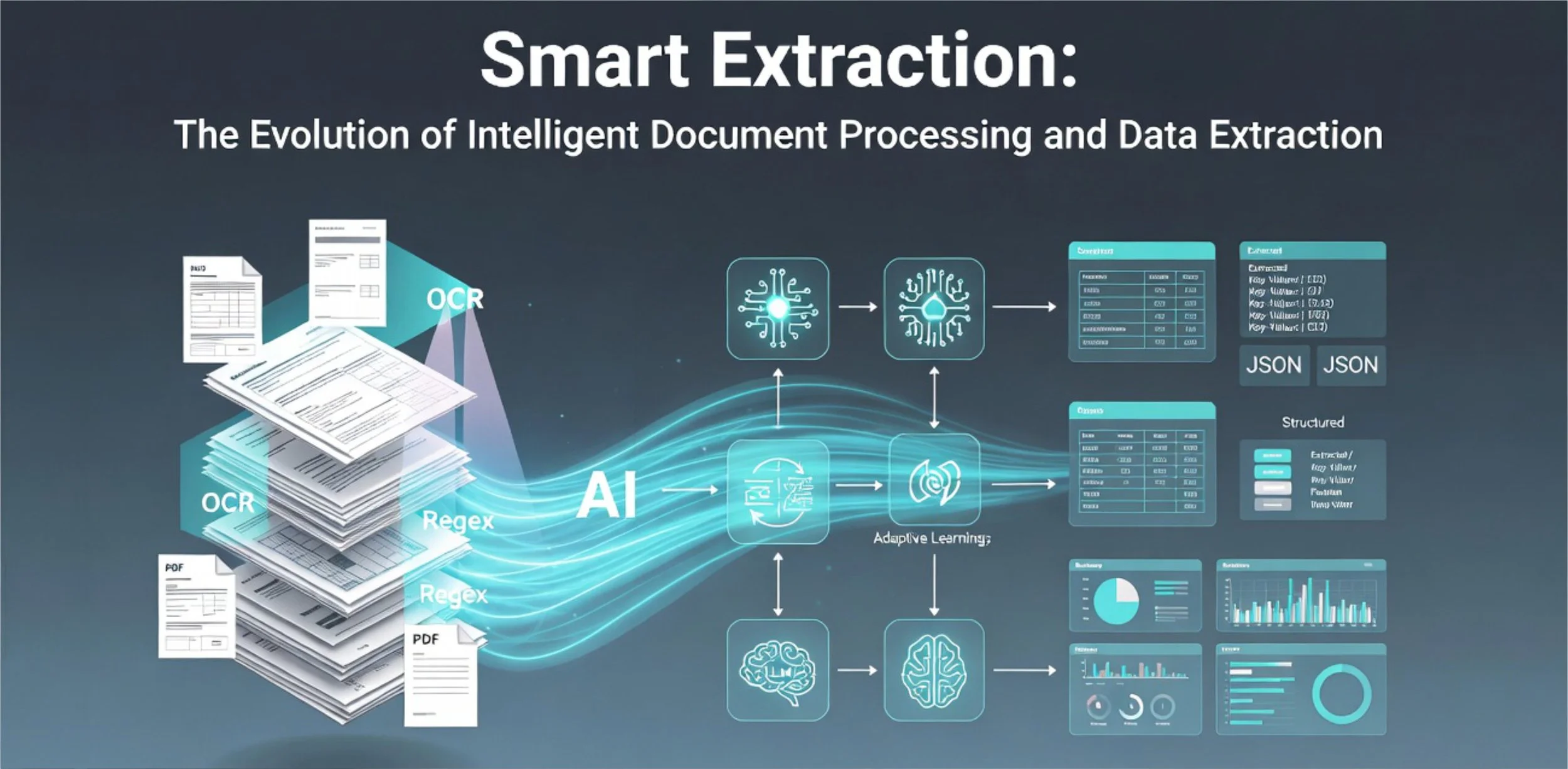
The journey of smart extraction is a fascinating one, evolving from basic but reliable traditional methods to today’s intelligent, adaptive systems. Understanding this evolution helps us see both where we stand today and the exciting possibilities ahead.
The Solid Foundations: OCR, Templates and Rules
It all started with Optical Character Recognition (OCR), the technology that converts scanned images and PDFs into readable text. Early OCR worked well for clear, printed documents, but it struggled with handwriting, poor quality scans, or unusual layouts. Businesses then added template-based extraction, defining specific zones on a page to pull out key information – particularly useful for standard invoices from regular suppliers.
Rule-based methods, such as regular expressions (regex), were layered on top to catch patterns like dates, account numbers or email addresses. These traditional approaches were fast, cost-effective, and highly reliable when document formats remained consistent. Many South African organisations still successfully use them for repetitive, high-volume tasks.
However, as document variety increased – with new suppliers, changing regulations, and different formats arriving daily – these rigid methods began to show their limits. A small change in layout often meant manual updates and frustrated teams.
The Intelligent Leap: Deep Learning and Adaptive Systems
Deep learning brought the first real breakthrough. Using advanced neural networks and models that understand both text and layout, systems became far better at handling semi-structured documents such as varied invoices or contracts. Accuracy improved significantly without the need for countless rules.
What truly changed the game was adaptive learning. Modern platforms learn from human corrections in real time. When a team member fixes an extracted field, the system gets smarter. This continuous improvement means less maintenance, higher accuracy over time, and genuine resilience to changing document formats. For many of us, this human-in-the-loop approach feels right – technology supporting people rather than replacing them.
Organisations that have adopted these methods often report 50 to 70 percent faster processing, substantial cost savings, and far fewer errors. In sectors such as finance, insurance, and healthcare, this also means stronger compliance and greater peace of mind.
The New Frontier: Large Language Models and Hybrid Solutions
Today, Large Language Models (LLMs) and multimodal AI are opening even more possibilities. These systems do not simply read text – they understand context, meaning, and intent. They can extract data from wildly different documents, often with little to no prior training.
Yet the most successful implementations today are hybrid. They combine reliable OCR and deep learning for accurate text and layout recognition, adaptive learning for ongoing improvement, and LLMs for handling complex cases and reasoning. This balanced approach delivers the high accuracy, cost efficiency, and transparency that professional environments demand.
Looking Ahead with Confidence
The future of smart extraction is moving beyond simple data pulling towards fully intelligent, agentic workflows. Documents will not only be processed – they will trigger actions, feed analytics, and support better decision-making automatically.
With data volumes continuing to rise rapidly, the organisations that embrace smart extraction will gain a real competitive advantage: faster insights, lower risk, happier teams, and the ability to focus on what matters most.
If you are feeling the pressure of document overload in your organisation, know that you are not alone. The good news is that practical, powerful solutions exist today – from proven traditional methods right through to cutting-edge intelligent systems. Investing in smart extraction is ultimately an investment in your people and your future success.
The question is no longer whether you should adopt it, but how quickly you can begin reaping the benefits.